HashMap总结
HashMap总结
基本原理类
1. 数据结构类
1.1 HAshMap的结构是什么?
JDK1.7是数组+链表
JDK1.8是数组+链表+红黑树
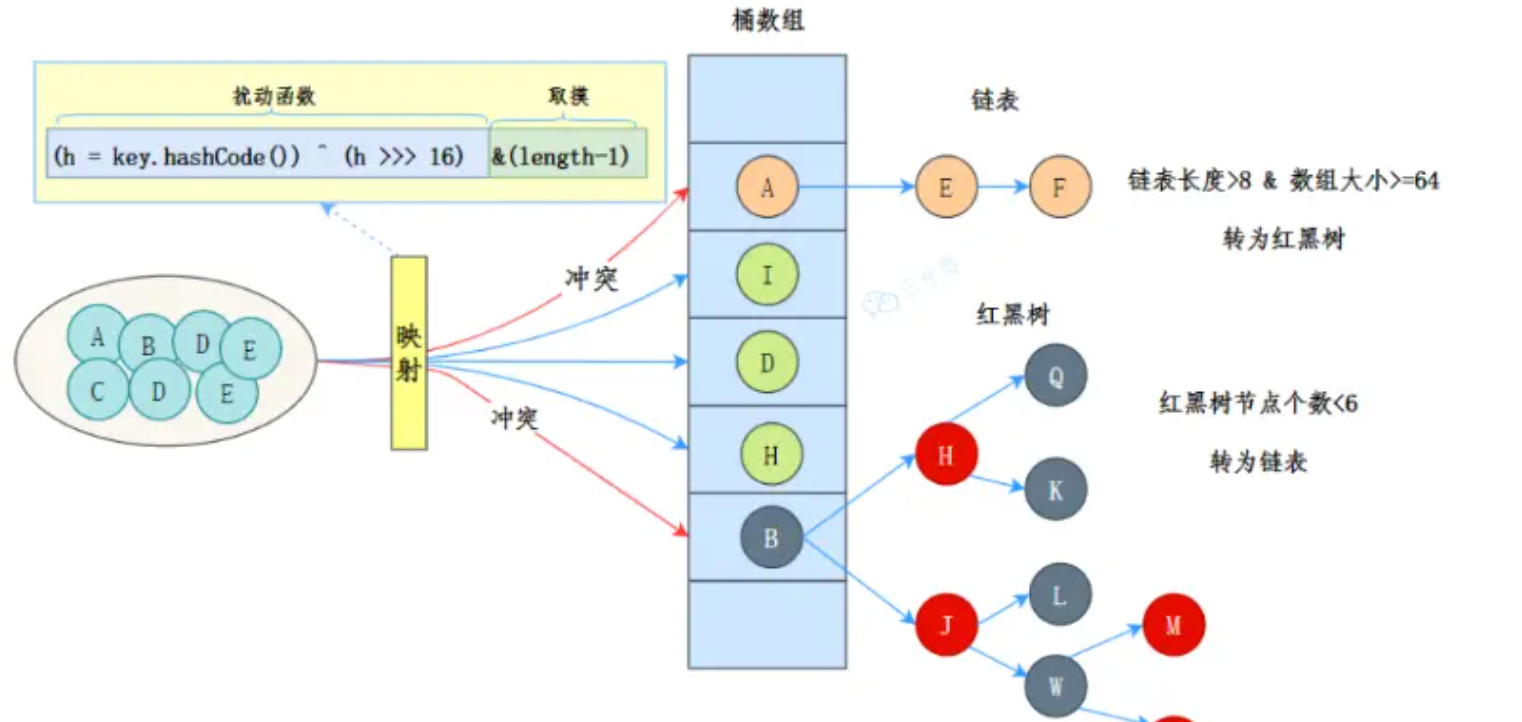
1.2 为什么要使用红黑树,什么时候转化为红黑树?
链表过长导致性能问题
- 在JDK1.8之前,HashMap采用数组加链表的结构。当多个键的哈希值存储到同一个桶中时,这些键值对会以链表的形式存储。
- 如表链表过长,会严重影响查询,插入和删除的性能,时间复杂度从O(1)到O(n)。
- 特别是在哈希严重冲突的情况下,链表的性能问题尤为明显。
红黑树的优势
- 红黑树是一种自平衡的二叉搜索树,它的查询,插入和删除的时间复杂度都是O(logn)。
- 当链表的长度超过一定的阈值(默认是8),HashMap会将链表转化为红黑树
- 这种优化在哈希冲突严重的情况下,可以显著提升性能。
- 链表转红黑树的阈值: 默认是8
- 红黑树退化为链表的阈值: 默认是6
2. 容量&Hash冲突
2.1 什么时候会扩容
当当前存储的键值对数量(size)超过了负载因子(load Factory)和 当前数组桶的数量(capacity)的乘积
扩容条件: size > loadFactory × capacity
负载因子默认为: 0.75 (经验值)
负载因子的影响:
负载因子过大:
- 优点:减少扩容次数,较少内存占用
- 缺点:哈希冲突的概率变大,造成查询,插入和删除的效率变低
负载因子过小:
- 优点:哈希冲突的概率较低,造成查询,插入和删除的效率高
- 缺点:频繁扩容,导致空间利用率低,内存消耗大
2.3 扩容步骤
当满足扩容条件时,HashMap会执行以下步骤:
创建新数组
新数组的容量是原数组的两倍
重新哈希(rrehash)
重新计算原数组中的值的哈希值,并根据新数组的长度计算其在新数组中的位置
迁移数据
将换数组中的键值对迁移到新数组中去
3. 数值问题
3.1 size为什么是2的n次方
高效计算索引
HashMap需要通过哈希值来确定键值对存储的数组索引,其公式为:
index = hash & (length -1)
其中:
hash是键的哈希值。length是数组的长度。&是按位与操作。
为什么是 length -1 ?
- 当
length是 2 的 n 次方时,length - 1的二进制表示是一串连续的 1。 - 通过
hash & (length - 1),可以快速将哈希值映射到[0, length - 1]的范围内。 - 这种方式比取模运算(
hash % length)更高效,因为位运算的速度远快于取模运算。
均匀分布索引
- 当 length 是 2 的 n 次方时,hash & (length - 1) 的结果能够均匀分布在 [0, length - 1] 的范围内。
- 这样可以减少哈希冲突,提高 HashMap 的性能。
反例:如果 length 不是 2 的 n 次方 - 例如,length = 15,则 length - 1 = 14,二进制为 1110。
- 在这种情况下,hash & (length - 1) 的结果会丢失最低位的 1,导致某些索引永远不会被使用(例如索引 1、3、5 等)。
- 这会增加哈希冲突的概率,降低 HashMap 的性能。
扩容时的优化
- HashMap 在扩容时,新数组的长度是原数组的两倍(即仍然是 2 的 n 次方)。
- 扩容后,键值对的索引要么保持不变,要么增加原数组的长度。
- 例如,原数组长度是 16,扩容后长度是 32。
- 如果原索引是 5,扩容后索引可能是 5 或 21(即
5 + 16)。
例子:
0101 &(0111)=0101(5)
变成32之后
0101&(1111)=0101(5)
- 这种特性使得扩容时只需要重新计算部分键值对的索引,而不需要重新计算所有键值对的索引,从而提高了扩容的效率。
哈希函数的优化
- HashMap 的哈希函数会对键的
hashCode()进行二次哈希,以减少哈希冲突。 - 当数组长度是 2 的 n 次方时,二次哈希的结果能够更好地分散在数组中,进一步减少哈希冲突。
3.2 hash值是如何计算的
- HashMap 使用以下公式对初始哈希值进行二次哈希计算:
1 | static final int hash(Object key) { |
h >>> 16:将哈希值右移 16 位,相当于将高 16 位移动到低 16 位。h ^ (h >>> 16):将原始哈希值的高 16 位与低 16 位进行异或运算。
举个例子:
假如 hashCode : 10001101_11010001_10001001_10101001
hashCode>>> 16= 00000000_00000000_10001101_11010001
长度=16时,只有后四位参与了运算。1111
索引计算:
通过二次哈希计算得到的哈希值,HashMap 会进一步计算键值对存储的桶索引。计算公式为:
index=hash&(length−1)
- 二次哈希的目的是将哈希值的高位信息混合到低位中,从而增加哈希值的随机性。
- 这样可以减少哈希冲突,特别是在 HashMap 的数组长度较小时。
流程问题
4.1 put操作
- HashMap 使用以下公式对初始哈希值进行二次哈希计算:
1 | static final int hash(Object key) { |
h >>> 16:将哈希值右移 16 位,相当于将高 16 位移动到低 16 位。h ^ (h >>> 16):将原始哈希值的高 16 位与低 16 位进行异或运算。
举个例子:
假如 hashCode : 10001101_11010001_10001001_10101001
hashCode>>> 16= 00000000_00000000_10001101_11010001
长度=16时,只有后四位参与了运算。1111
索引计算:
通过二次哈希计算得到的哈希值,HashMap 会进一步计算键值对存储的桶索引。计算公式为:
index=hash&(length−1)
- 二次哈希的目的是将哈希值的高位信息混合到低位中,从而增加哈希值的随机性。
- 这样可以减少哈希冲突,特别是在 HashMap 的数组长度较小时。
4.2 扩容
1 | final Node<K, V>[] resize() { |
线程安全
1. HashMap和HashTable的区别:
- 线程安全性
- HashTable:是线程安全的,所有方法都用
synchronized修饰,适合多线程环境,但性能较低。 - HashMap:非线程安全,性能更高,适合单线程环境。多线程时需手动同步或使用
Collections.synchronizedMap或ConcurrentHashMap。
- 是否允许 null 键和值
- HashTable:不允许
null键或值,否则会抛出NullPointerException。 - HashMap:允许一个
null键和多个null值。
- 继承关系
- HashTable:继承自
Dictionary类。 - HashMap:继承自
AbstractMap类。
- 迭代器
- HashTable:使用
Enumeration进行迭代,不支持快速失败机制。 - HashMap:使用
Iterator,支持快速失败机制,迭代时若结构被修改会抛出ConcurrentModificationException。
- 性能
- HashTable:由于同步开销,性能较差。
- HashMap:无同步开销,性能更好。
- 初始容量和扩容
- HashTable:默认初始容量为 11,扩容为
2n + 1。 - HashMap:默认初始容量为 16,扩容为
2n。
- 哈希算法
- HashTable:直接使用对象的
hashCode。 - HashMap:对
hashCode进行二次哈希以减少冲突。
2. 线程安全的MAP有哪些
| 实现方式 | 线程安全机制 | 是否允许 null 键值 | 性能 | 有序性 |
|---|---|---|---|---|
| Hashtable | 全表锁 | 不允许 | 较低 | 无序 |
| Collections.synchronizedMap | 全表锁 | 允许 | 中等 | 无序 |
| ConcurrentHashMap | 分段锁/CAS | 不允许 | 高 | 无序 |
| ConcurrentSkipListMap | 跳表 | 不允许 | 较高 | 有序 |
| ImmutableMap | 不可变 | 允许 | 最高 | 无序 |
3. ConcurrentHashMap在1.7和1.8的区别
| 特性 | JDK 7 | JDK 8 |
|---|---|---|
| 数据结构 | 分段锁(Segment 数组 + HashEntry 链表) | Node 数组 + 链表/红黑树 |
| 锁机制 | 分段锁(每个 Segment 继承 ReentrantLock) | CAS + synchronized(锁单个 Node) |
| 锁粒度 | 锁住整个 Segment | 锁住单个 Node |
| 并发性能 | 较低(锁粒度较大) | 较高(锁粒度更小,减少锁竞争) |
| 内存占用 | 较高(每个 Segment 独立维护哈希表) | 较低(去除了 Segment,结构更紧凑) |
| 扩容机制 | 分段扩容(每个 Segment 独立扩容) | 整体扩容(动态调整 Node 数组大小) |
| 哈希冲突处理 | 链表 | 链表 + 红黑树(链表过长时转换为红黑树) |
| 红黑树支持 | 不支持 | 支持(链表长度超过阈值时转换为红黑树) |
| 迭代器一致性 | 弱一致性 | 弱一致性 |
| null 键值支持 | 不允许 null 键或值 | 不允许 null 键或值 |
| 动态调整 | 不支持动态调整 Segment 数量 | 支持动态调整 Node 数组大小 |
| 实现复杂度 | 较高(分段锁机制复杂) | 较低(CAS + synchronized 实现更简洁) |
| 适用场景 | 中等并发场景 | 高并发场景 |
Map工具类
Maps是Guava中常用的map工具类,具体如下:
| 方法 | 功能描述 | 示例 |
|---|---|---|
| Maps.newHashMap() | 创建一个空的 HashMap。 | Map<String, Integer> map = Maps.newHashMap(); |
| Maps.newLinkedHashMap() | 创建一个空的 LinkedHashMap。 | Map<String, Integer> map = Maps.newLinkedHashMap(); |
| Maps.newTreeMap() | 创建一个空的 TreeMap。 | Map<String, Integer> map = Maps.newTreeMap(); |
| Maps.newConcurrentMap() | 创建一个空的 ConcurrentHashMap。 | Map<String, Integer> map = Maps.newConcurrentMap(); |
| Maps.newHashMapWithExpectedSize(int expectedSize) | 创建一个 HashMap,并根据预期大小优化初始容量。 | Map<String, Integer> map = Maps.newHashMapWithExpectedSize(10); |
| Maps.newLinkedHashMapWithExpectedSize(int expectedSize) | 创建一个 LinkedHashMap,并根据预期大小优化初始容量。 | Map<String, Integer> map = Maps.newLinkedHashMapWithExpectedSize(10); |
| Maps.uniqueIndex(Iterable |
根据 keyFunction 从 Iterable 中提取键,创建一个 Map。 | Map<String, Person> map = Maps.uniqueIndex(persons, Person::getId); |
| Maps.asMap(Set |
根据 keys 和 valueFunction 创建一个 Map,值为 valueFunction 的计算结果。 | Map<String, Integer> map = Maps.asMap(keys, k -> k.length()); |
| Maps.filterKeys(Map<K, V> map, Predicate |
过滤 Map,保留满足 keyPredicate 的键值对。 | Map<String, Integer> filtered = Maps.filterKeys(map, k -> k.startsWith(“a”)); |